
知新网站爬虫分析
知新网站的爬虫分析
正在更新中...
前言
知新网站,我总是喜欢偷懒,有些时候,感觉C语言出的题太简单了,不太想做,也可能是很早接触编程语言,让我自我感觉良好,所以就像偷偷懒,所以本次来分析一下知新网站的一些功能。
当然,也希望网站可以做的更好,修复一些bug。
配置准备
在本次分析中,我们需要准备好以下部分:
- 基本的爬虫知识
- 基本的分析能力
- 基本的HTML、CSS、JavaScript等知识
注意:本次分析仅供参考(2024-12-31), 网站可能已经发生变化,本文不再更新。
同时,本次分析仅供个人学习交流使用,请勿用于真正环境
本次分析并不提供真实代码
目标
- 分析知新网站的登陆功能
- 分析知新网站的课后作业功能
- 分析知新网站的作业提交功能
网站分析
登陆界面
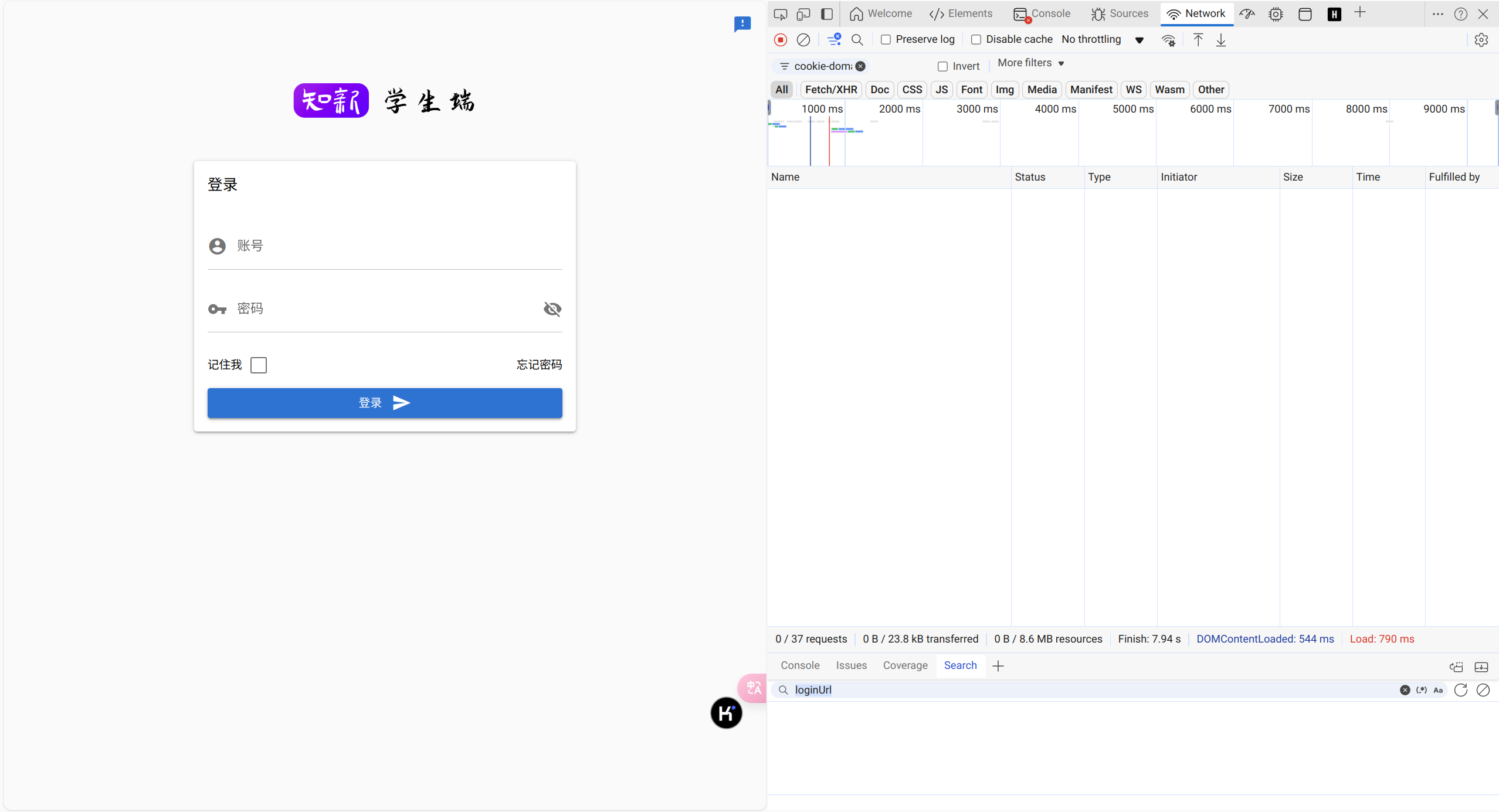
大家可以输入账号密码试试,这右侧并不会有什么东西出现,大家要保持调试模式,输入账号密码进行下一步操作。
首页
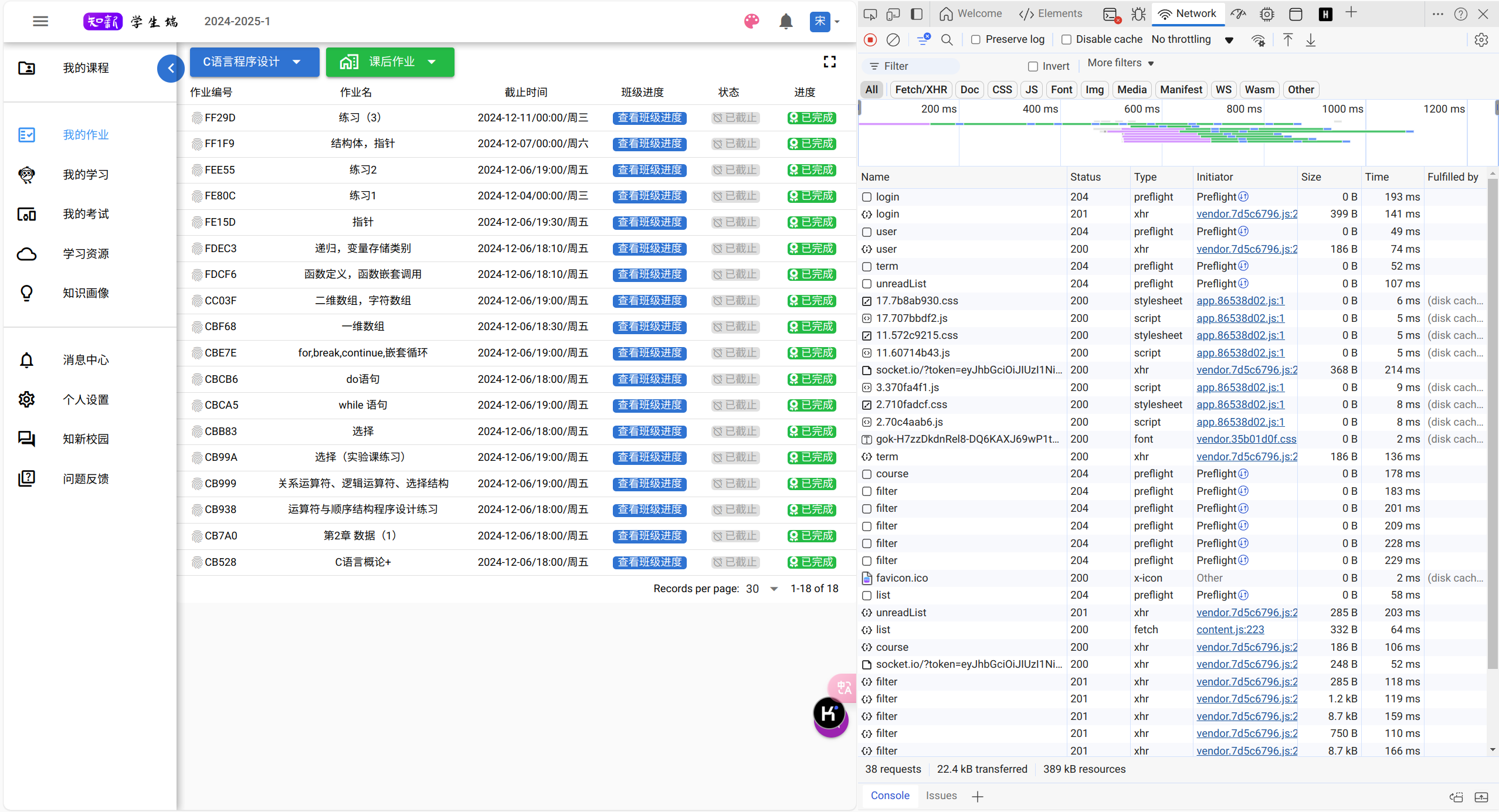
如果,我们要实现爬虫,我们第一步就是要实现登陆的功能,所以我们分析右侧的网络。
我们可以注意到当中的login,我们来分析一下
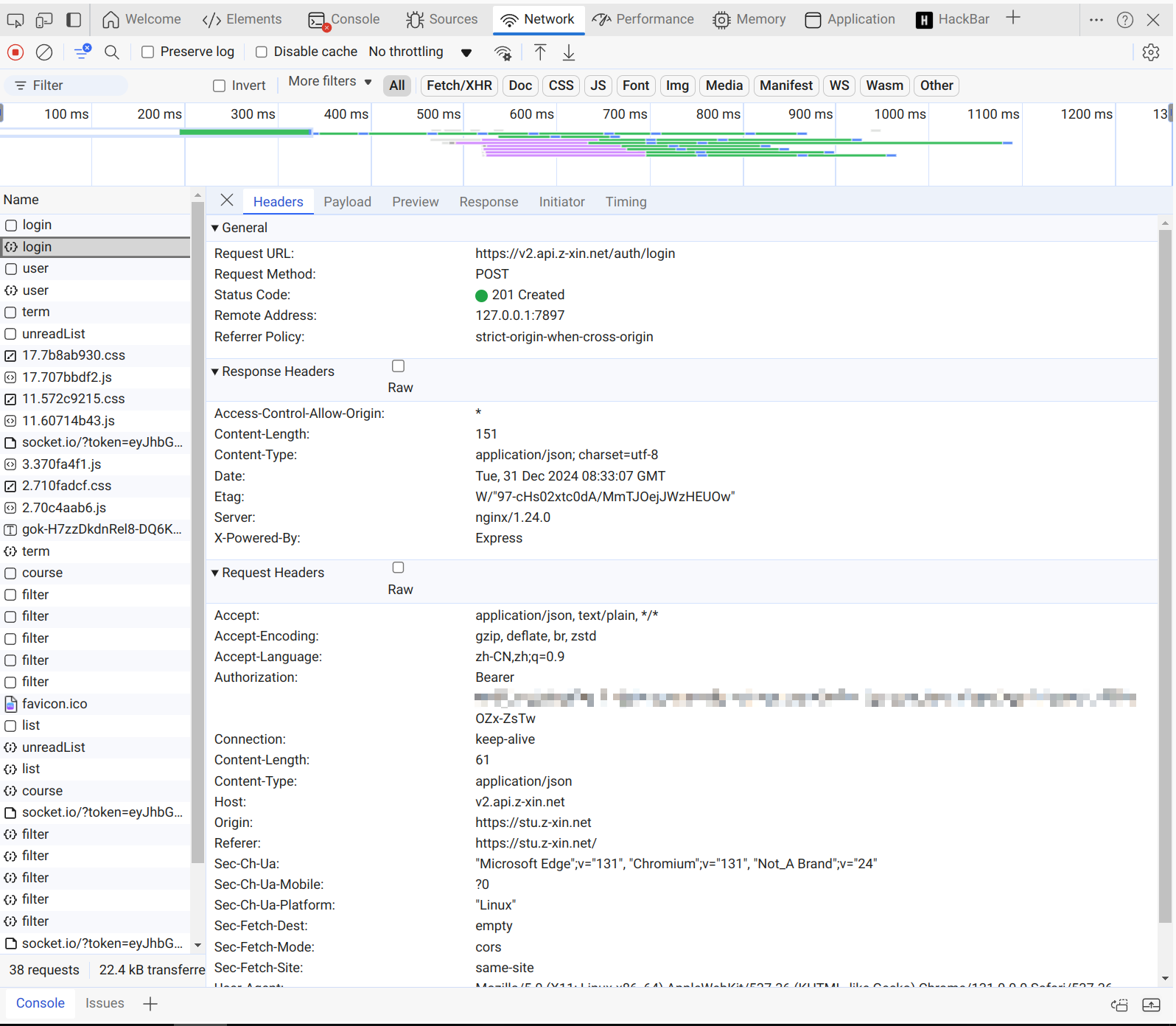
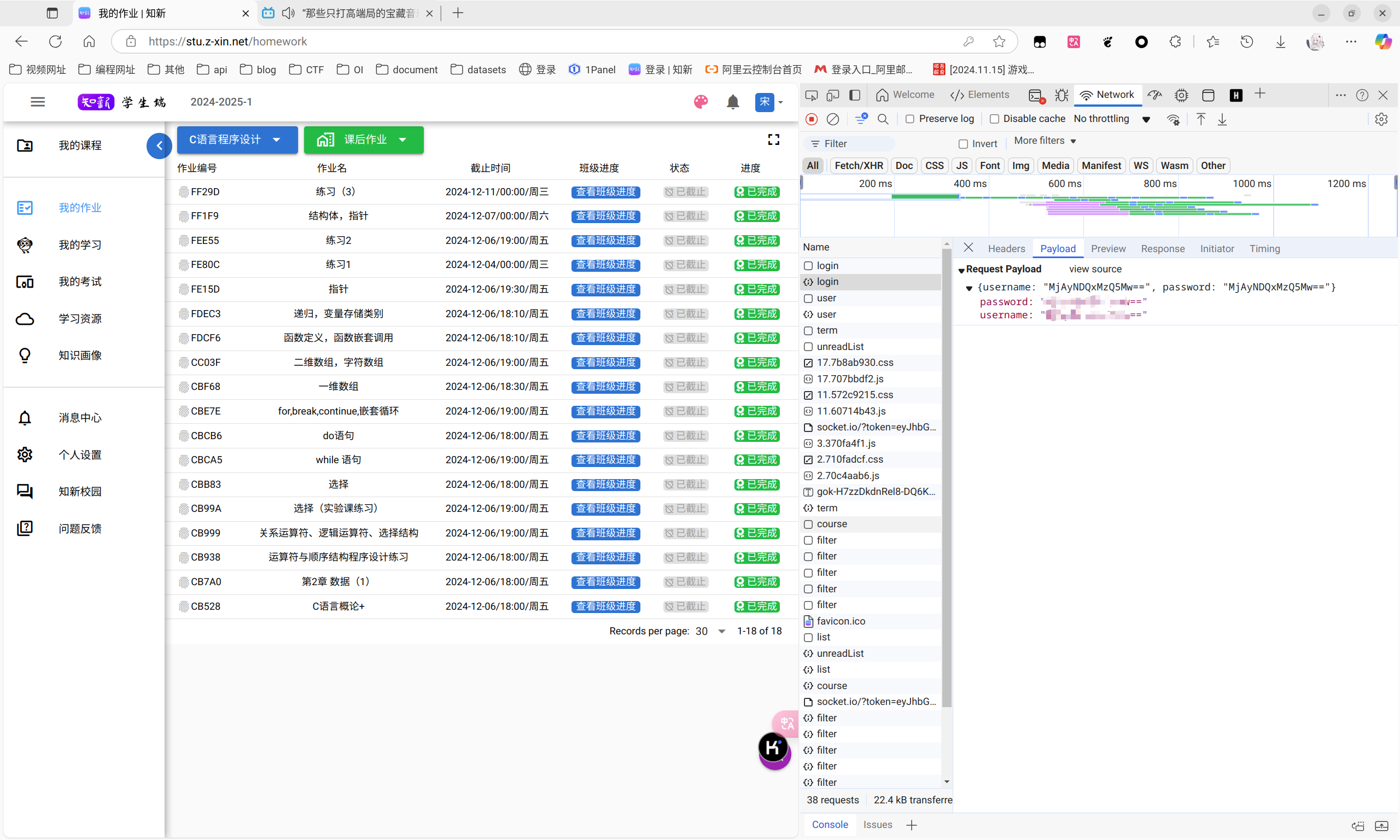
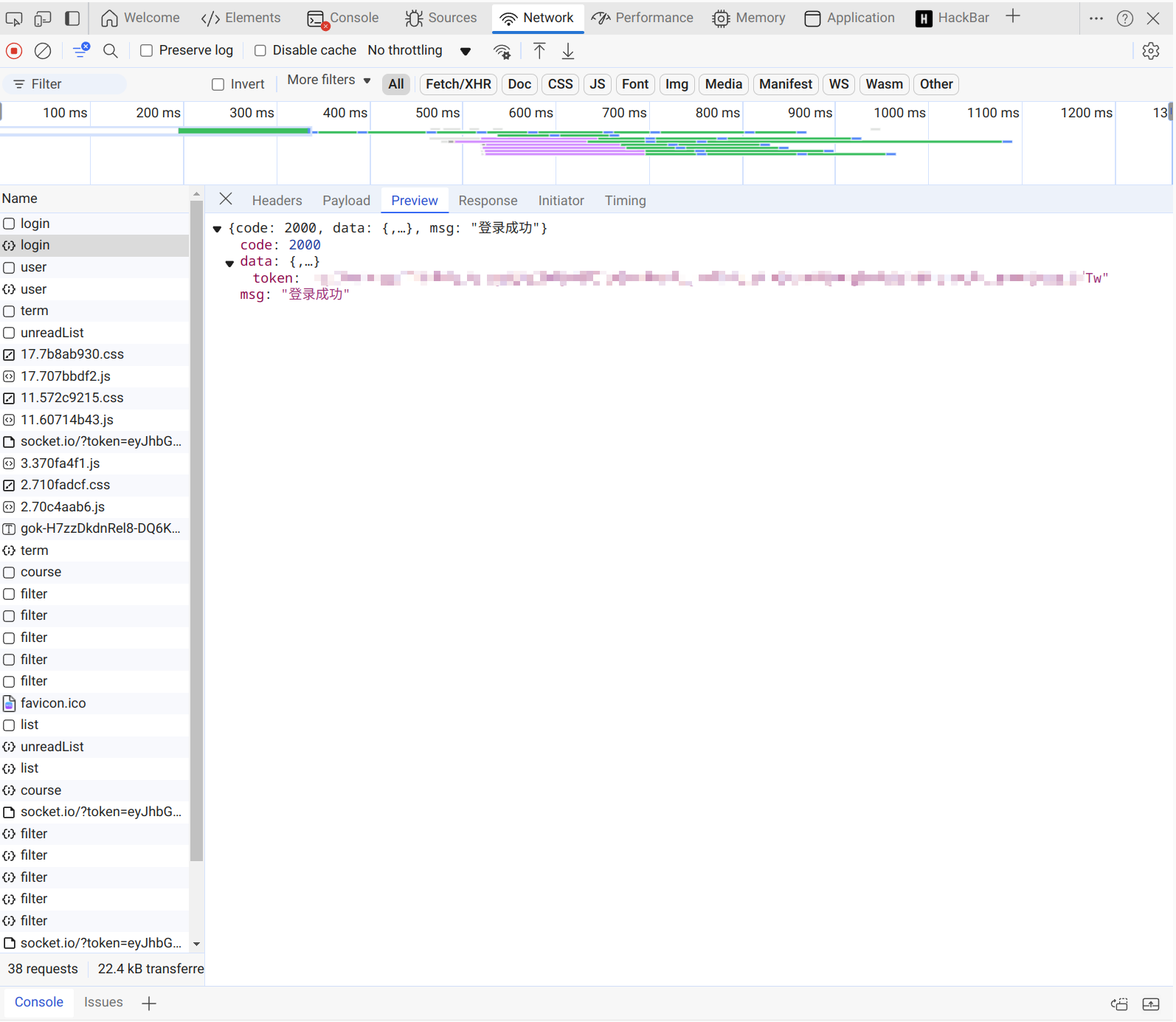
我们可以看到,当我们输入账号密码之后,会发送一个POST请求,然后服务器会返回一个token。
这个token可以在第一个图片中看到,发送请求的时候,在cookie,是附带着这个token的。
我们可以看到获取的
usrname和password后面都是有==这个标志的,大家了解的多了> 也就知道,这是一个很明显的base64编码(这玩意儿不能算加密)
所以,在这里想要拿到token,我们需要先进行base64编码,然后发送POST请求,获取到token。
然后在之后的操作中,请求头中需要带上这个
token(cookie中需要使用 )
很简单,对不对?
SGVsbG8gQmFzZTY0IQ==
用户信息
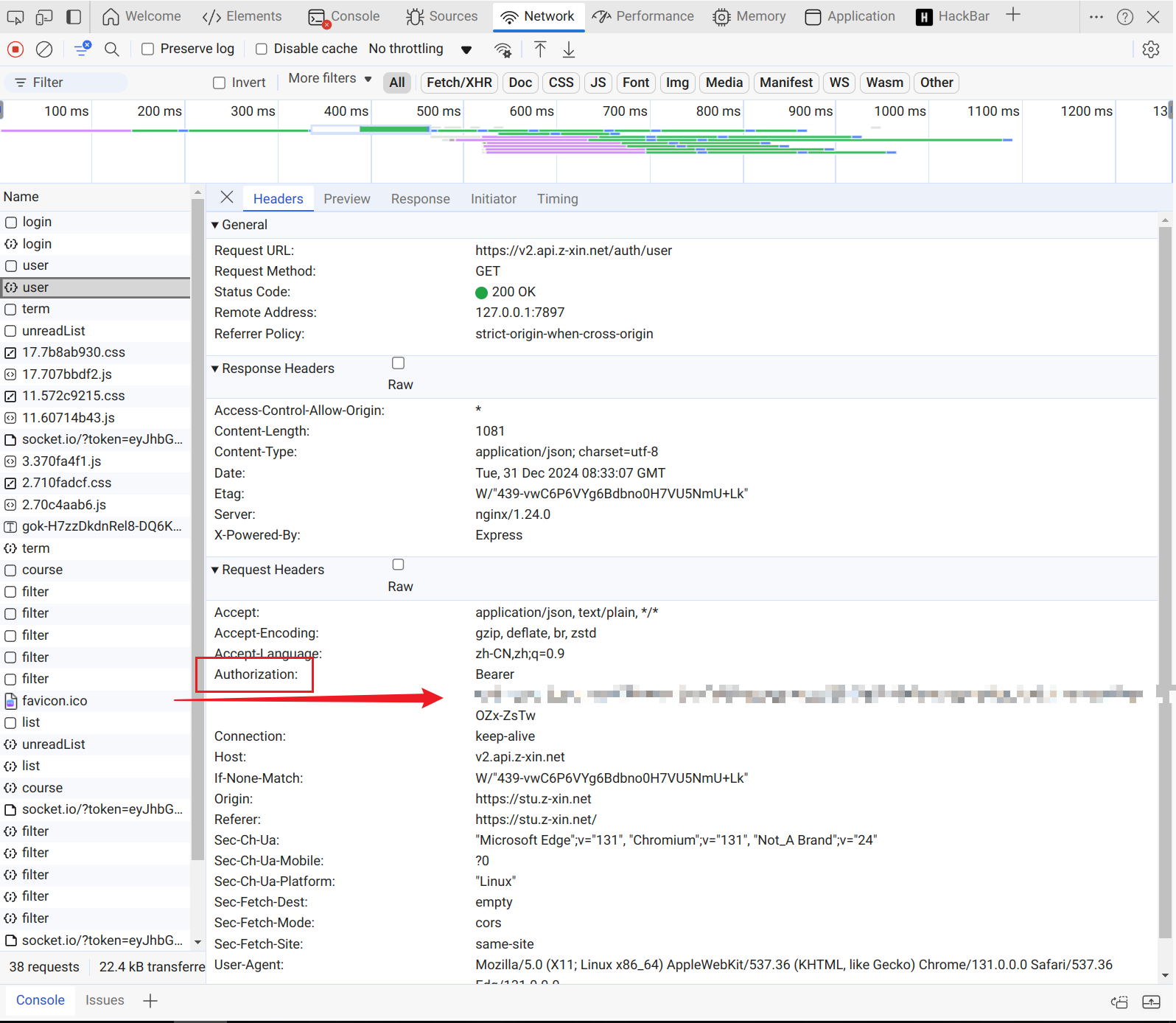
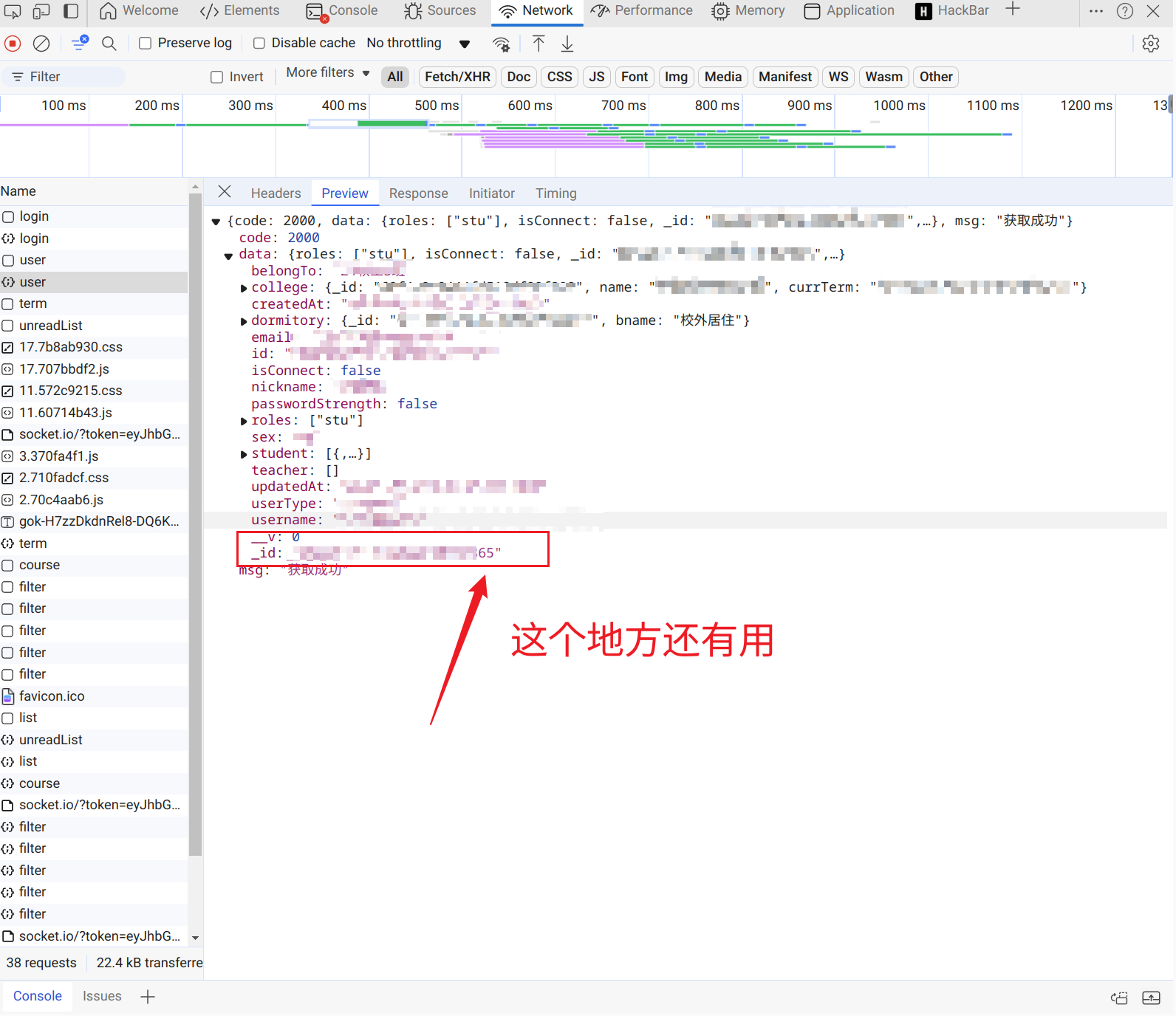
继续向下分析
爬虫很枯燥,需要我们不断的去分析,我们继续往下找。
课后作业
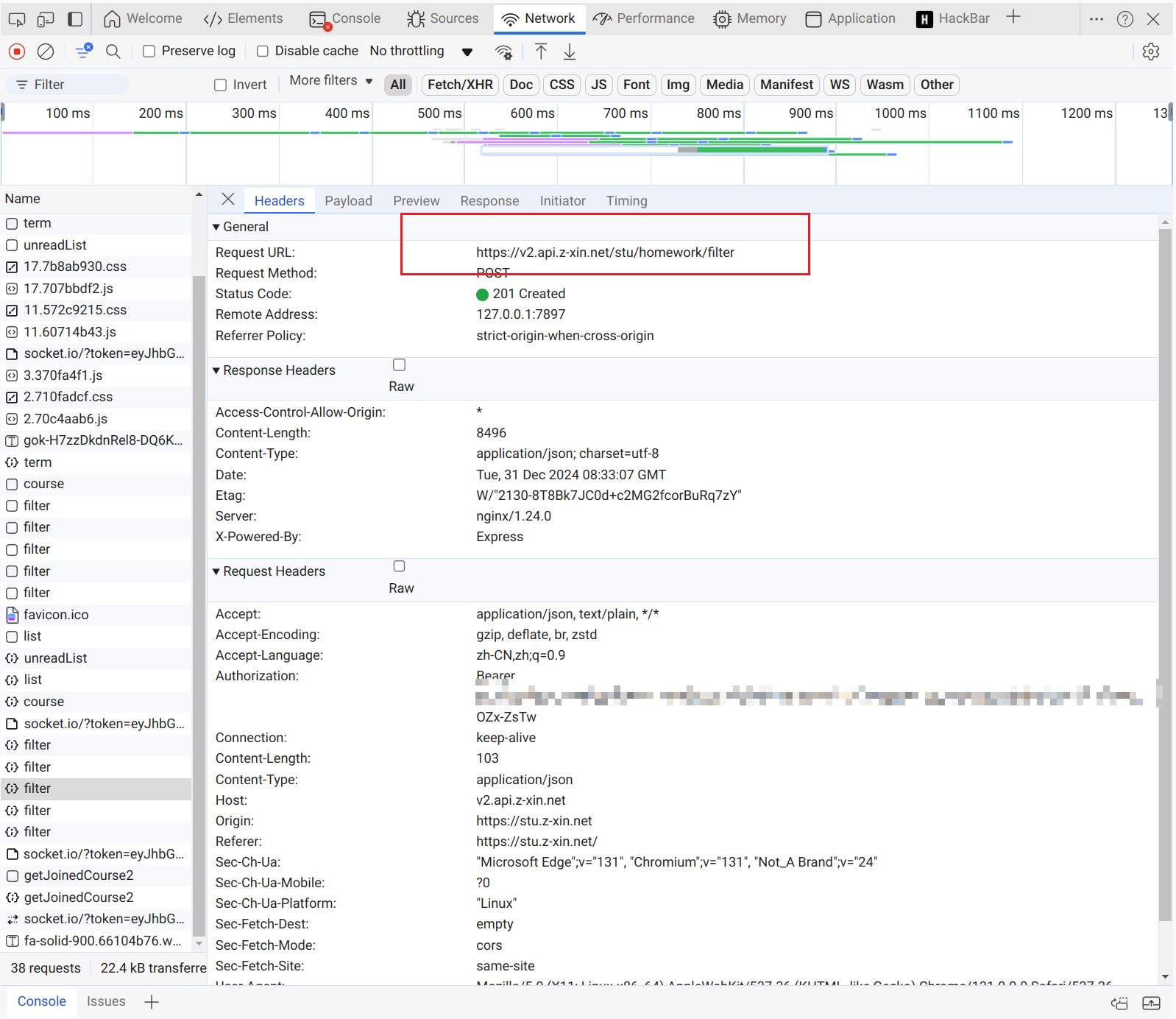
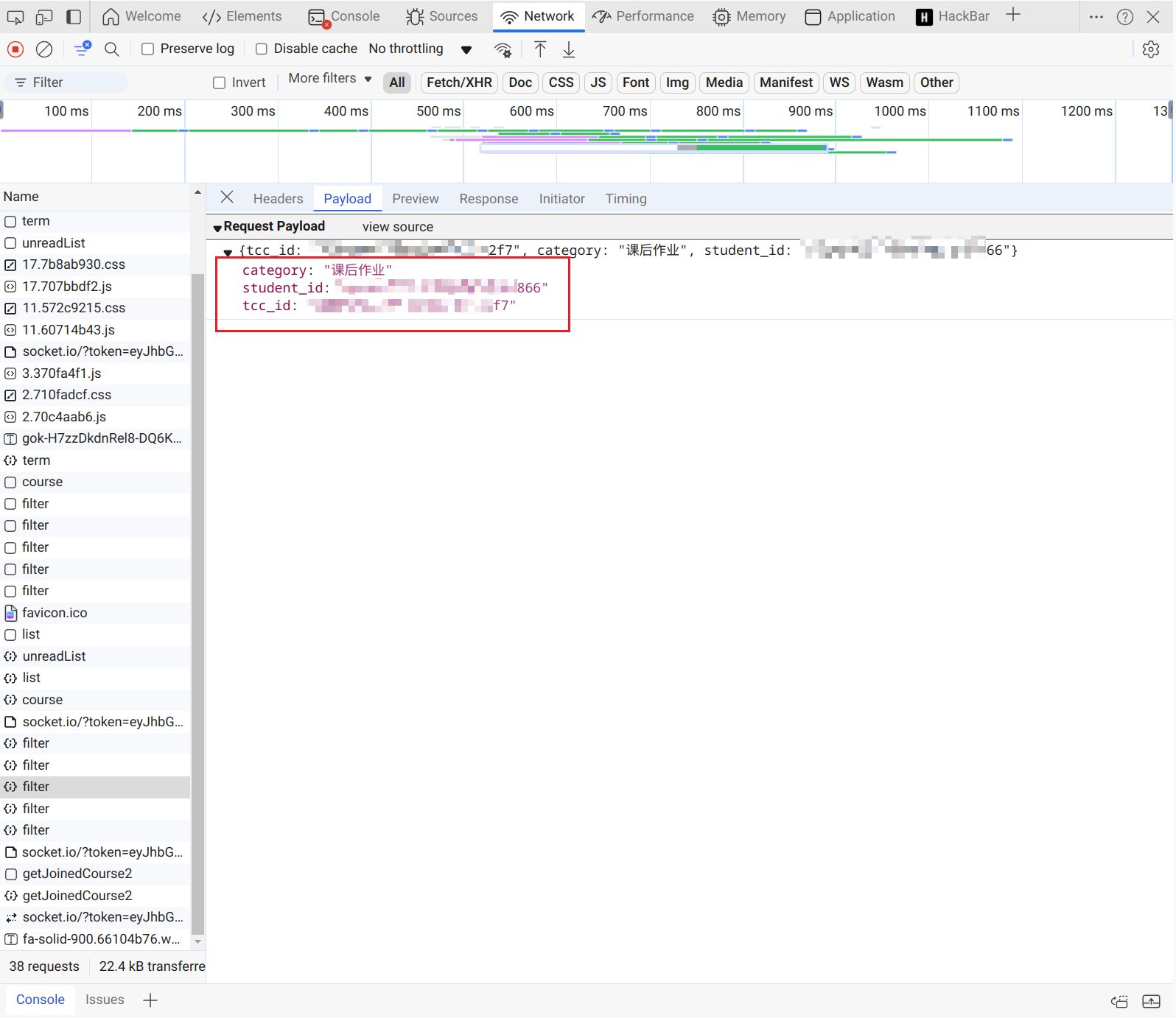
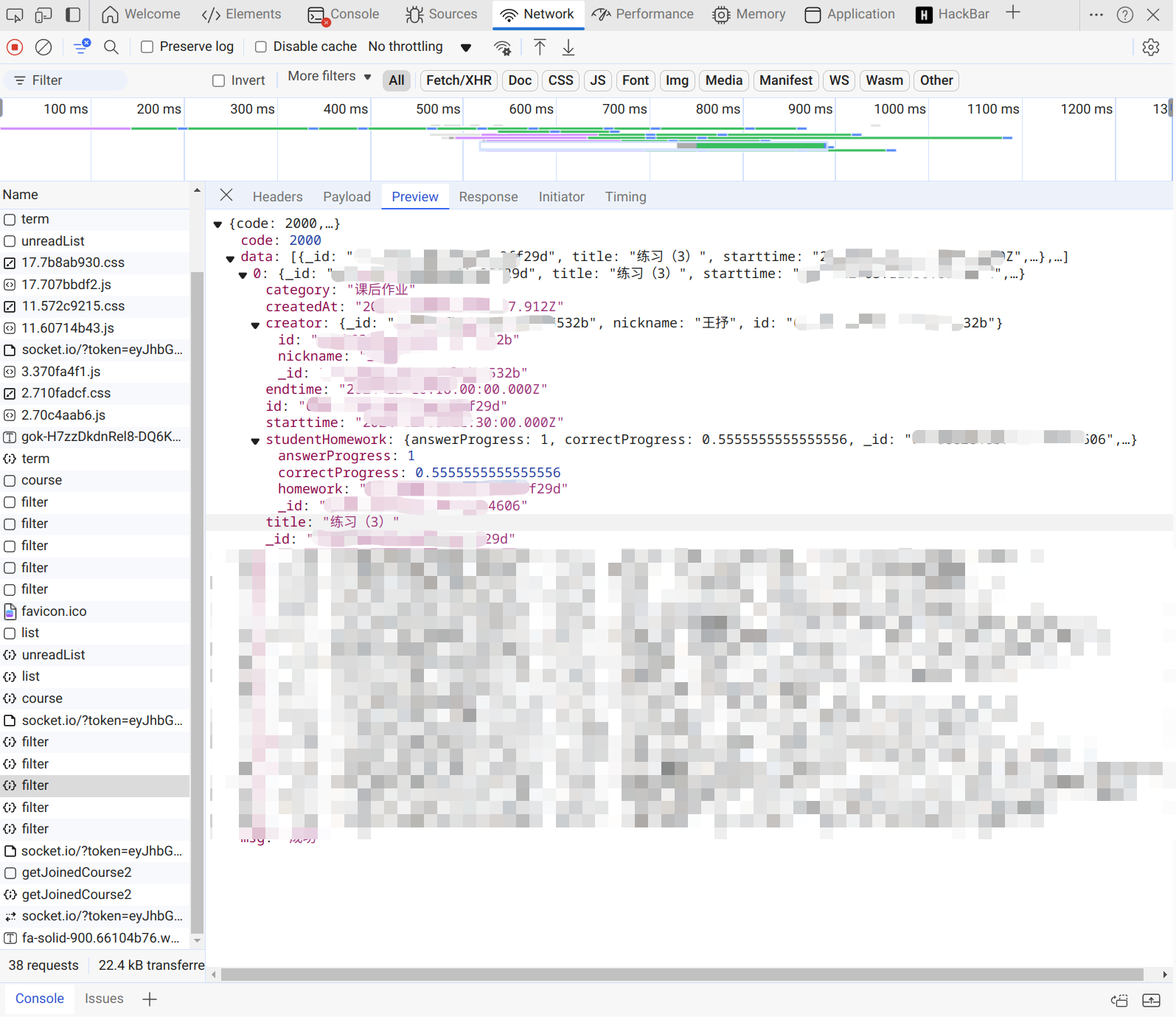
最后我们在https://v2.api.z-xin.net/stu/homework/filter中找到了我们的课后作业
既然找到了这些信息,就得看看我们做作业的网页与这里获取到的信息有什么联系.
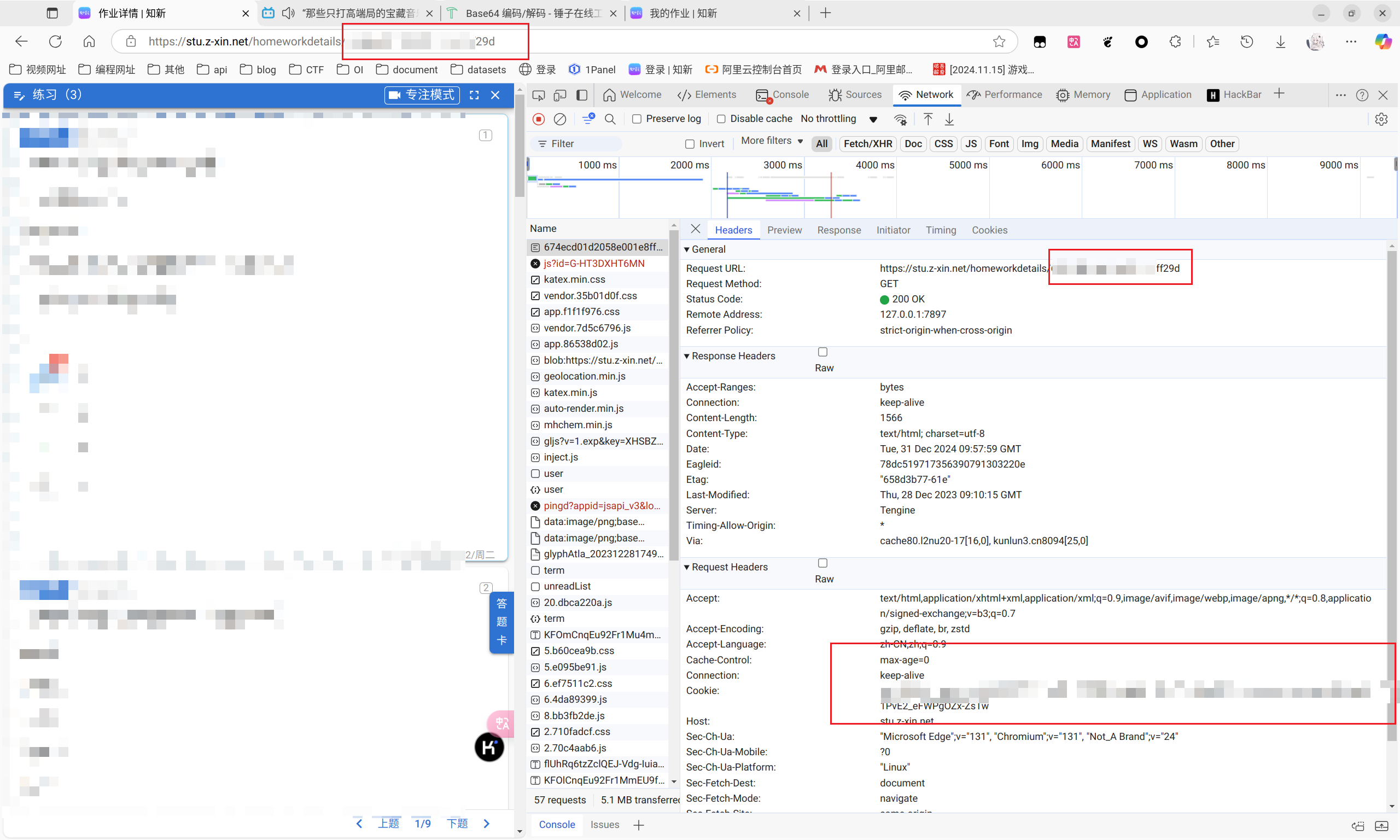
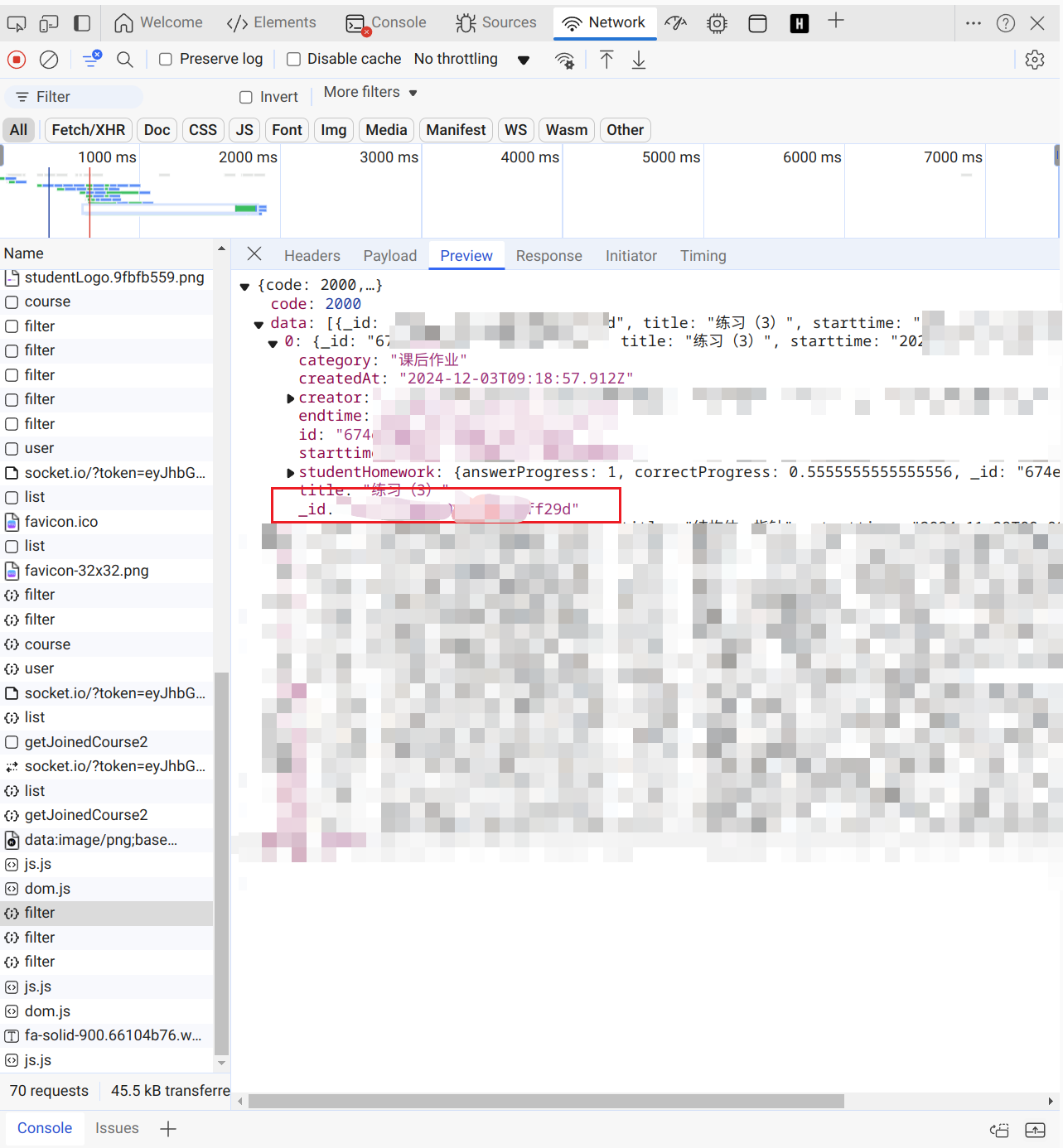
我们可以看到,我们在https://v2.api.z-xin.net/stu/homework/filter中获取到了作业的id和name,这就证明这里的内容很重要,我们的爬虫需要从这里找到其他作业。
接下来,我们分析这里的需要提交的json数据
homework/filter需要提交的json数据分析
我们在这里看到,我们的请求参数需要三个category,student_id和tcc_id
其中category是直接给出的,是课后作业。
student_id,我们一看到这个参数,我们应该去想到刚才我们分析的用户界面,我们现在过去看看,有没有。
我们可以看到,我们在用户界面中,有个id,但是,这个user里面分析到的id和我们在homework/filter中获取到的student_id是不一样的(相差了一个1),这就有点奇怪了。
我们先放下这个参数,分析另一个参数tcc_id
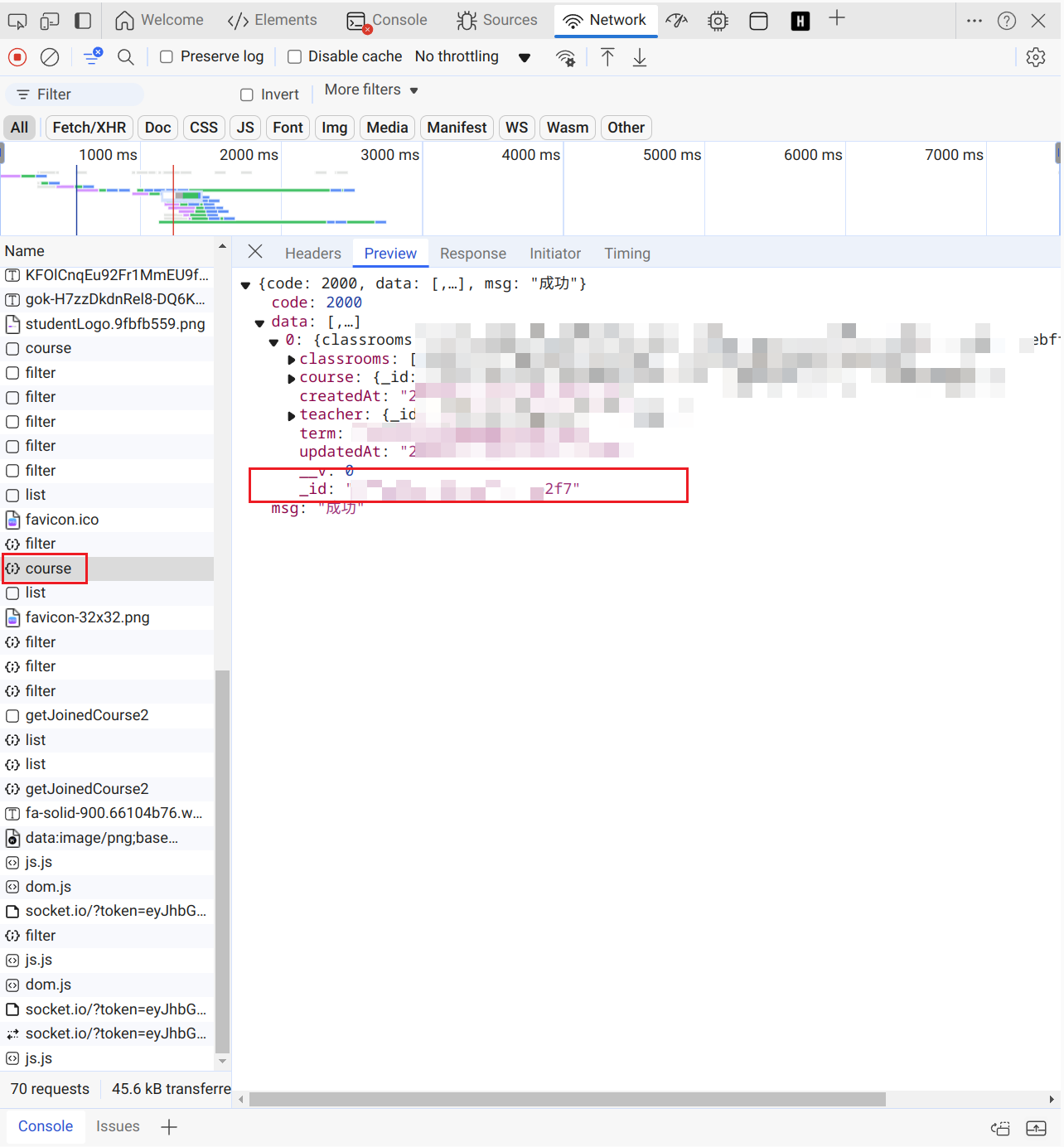
如果你是仔细,一步一步的分析过来的,你会发现在这里的一个参数与tcc_id也是相差一个1
我们再来看一下我们在
homework/filter中获取到的两个参数
student_id: ********66
tcc_id: ********f7而在我们在
user中获取到的_id: ********65在
cours中获取到的tcc_id: ********f6
真的是,好家伙,原来我们只需要在user中获取到_id,然后在cours中获取到tcc_id,然后这两个参数加1,就凑齐了我们要的三个参数了
这样我们就能实现知新网站的登陆功能,课后作业的获取的功能
我们讲解了请求头所必需的
cookie,以及对爬取课后作业所需数据的分析,代码不便展示,> 大家可以自行分析。
- 感谢你赐予我前进的力量
-
 微信
微信  支付宝
支付宝
